IPFS significa Sistema de Archivos Interplanetarios. En su esencia, es un sistema de archivos versionado que puede almacenar archivos y rastrear versiones a lo largo del tiempo, muy parecido a Git. También define cómo se mueven los archivos a través de una red, por lo que es un sistema de archivos distribuidos, al igual que BitTorrent. Al combinar estas dos propiedades, IPFS habilita una nueva web permanente y aumenta la forma en que usamos los protocolos de Internet existentes como HTTP.
En pocas palabras, Internet es una colección de protocolos que describen cómo se mueven los datos en una red. Los desarrolladores adoptaron estos protocolos a lo largo del tiempo y construyeron sus aplicaciones sobre esta infraestructura. Uno de los protocolos que sirve como la columna vertebral de la web es HTTP o HyperText Transfer Protocol. Esto fue inventado por Tim Berners-Lee en 1991.
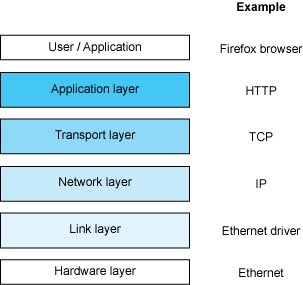
HTTP es un protocolo de solicitud-respuesta. Un cliente, por ejemplo, un navegador web, envía una solicitud a un servidor externo. El servidor luego devuelve un mensaje de respuesta, por ejemplo, la página de inicio de Google al cliente. Este es un protocolo con dirección de ubicación, lo que significa que cuando escribo google.com en mi navegador, se traduce a una dirección IP de algún servidor de Google, luego se inicia el ciclo de solicitud-respuesta con ese servidor.
Problemas con HTTP
Digamos que está sentado en una sala de conferencias y el profesor le pide que vaya a un sitio web específico. Todos los estudiantes de la clase hacen una solicitud a ese sitio web y reciben una respuesta. Esto significa que los mismos datos exactos se enviaron individualmente a cada estudiante en la sala. Si hay 100 estudiantes, entonces son 100 solicitudes y 100 respuestas. Obviamente, esta no es la forma más eficiente de hacer las cosas. Idealmente, los estudiantes podrán aprovechar su proximidad física para recuperar de manera más eficiente la información que necesitan.
HTTP también presenta una gran dificultad si hay algún problema en la línea de comunicación de las redes y el cliente no puede conectarse con el servidor. Esto puede suceder si un ISP tiene una interrupción, un país bloquea algún contenido o si simplemente se eliminó o se movió. Estos tipos de enlaces rotos existen en todas partes en la web HTTP.
El modelo de direccionamiento basado en la ubicación de HTTP fomenta la centralización. Es conveniente confiar en un puñado de aplicaciones con todos nuestros datos, pero debido a esto, gran parte de los datos en la web se vuelven aislados. Esto deja a esos proveedores con una enorme responsabilidad y poder sobre nuestra información.
¿Cómo funciona el IPFS?

IPFS busca crear una web permanente y distribuida. Para ello, utiliza un sistema con dirección de contenido en lugar del sistema basado en la ubicación de HTTP.
Una solicitud HTTP se vería como: http://10.20.30.40/folder/file.txt
Una solicitud de IPFS se vería como: /ipfs/QmT5NvUtoM5n/folder/file.txt
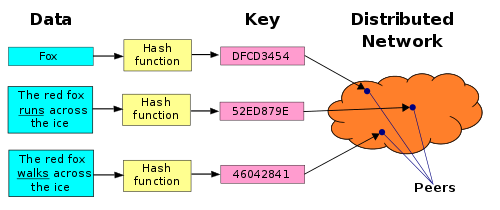
En lugar de utilizar una dirección de ubicación, IPFS utiliza una representación del contenido en sí para abordar el contenido. Esto se hace usando un hash criptográfico en un archivo y se usa como la dirección. El hash representa un objeto raíz y otros objetos se pueden encontrar en su ruta. En lugar de hablar con un servidor, obtiene acceso a este «punto de inicio» de los datos. De esta manera el sistema aprovecha la proximidad física. Si alguien muy cercano a mí tiene lo que quiero, lo obtendré directamente de ellos en lugar de conectarme a un servidor central. Con HTTP, se pregunta qué hay en una ubicación determinada, mientras que con IPFS se pregunta dónde se encuentra un determinado archivo. Para lograr esto, IPFS sintetiza algunas ideas exitosas de otros sistemas peer-to-peer.
IPFS y Blockchain
Este es uno de los casos de uso más emocionantes para IPFS. Un blockchain tiene una estructura DAG natural, ya que los bloques anteriores siempre están vinculados por su hash de los posteriores. Las cadenas de bloques más avanzadas, como la cadena de bloques Ethereum, también tienen una base de datos de estado asociada que tiene una estructura de árbol Merkle-Patricia que también se puede emular utilizando objetos IPFS.
Asumimos un modelo simplista de una cadena de bloques donde cada bloque contiene los siguientes datos:
- Una lista de objetos de transacción
- Un enlace al bloque anterior.
- El hash de un árbol de estado / base de datos
- Esta cadena de bloques se puede modelar en IPFS de la siguiente manera:

Un punto interesante aquí es la distinción entre almacenar datos en la cadena de bloques y almacenar hashes de datos en la cadena de bloques. En la plataforma Ethereum usted paga una tarifa bastante alta por almacenar datos en la base de datos estatal asociada, a fin de minimizar la hinchazón de la base de datos estatal («bloatch blockchain»). Por lo tanto, es un patrón de diseño común para piezas más grandes de datos para almacenar no los datos en sí, sino un hash IPFS de los datos en la base de datos del estado.
Si la cadena de bloques con su base de datos de estado asociada ya está representada en el IPFS, entonces la distinción entre almacenar un hash en la cadena de bloques y almacenar los datos en la cadena de bloques se vuelve un tanto borrosa, ya que todo está almacenado en el IPFS de todos modos, y el hash del bloque solo necesita El hash de la base de datos estatal. En este caso, si alguien ha almacenado un enlace IPFS en la cadena de bloques, podemos seguir este enlace sin problemas para acceder a los datos como si los datos estuvieran almacenados en la propia cadena de bloques.
Sin embargo, aún podemos hacer una distinción entre el almacenamiento de datos dentro y fuera de la cadena. Hacemos esto mirando lo que los mineros necesitan procesar al crear un nuevo bloque. En la red actual de Ethereum, los mineros necesitan procesar transacciones que actualizarán la base de datos del estado. Para hacer esto, necesitan acceso a la base de datos de estado completo para poder actualizarla donde sea que se cambie.
Por lo tanto, en la base de datos de estado de la cadena de bloques representada en el IPFS todavía tendríamos que etiquetar los datos como «en cadena» o «fuera de cadena». Los datos «en cadena» serían necesarios para que los mineros los retengan localmente con el fin de extraerlos, y estos datos se verían directamente afectados por las transacciones. Los usuarios tendrían que actualizar los datos «fuera de cadena» y los mineros no deberían tocarlos.
Conclusiones
IPFS es un sistema de archivos distribuido que busca conectar todos los dispositivos informáticos con el mismo sistema de archivos. De alguna manera, esto es similar a los objetivos originales de la Web, pero IPFS es en realidad más similar a un único enjambre bittorrent intercambiando objetos GIT.
IPFS podría convertirse en un nuevo subsistema importante de internet. Si se construye correctamente, podría complementar o reemplazar HTTP. Se podría complementar o reemplazar aún más.
Autores: Ingmar Frey y Raymundo Cámara Sánchez.
Patrocinado por: Consultores EMKT SA de CV.

Deja un comentario